Phase I-Search Book Information
- mbbhavana9
- Oct 10, 2019
- 3 min read
Updated: Sep 3, 2020
In book search, user will be able to search for books with free text.
Implemented text search feature using TF-IDF algorithm.
Before applying TF-IDF algorithm, data should be pre-processed.
For this, removed stop words and used Snowball stemming.

Using TF-IDF we can compute weight of each word in the document, which represents how important each word is for document.
TF-IDF = TF*IDF
In this TF is how frequent a term appears in a document. This can normalized by dividing the frequency of word with total number of words in document.
TF = (number of times term appears in a document) /(total number of words in that particular document)
IDF = (total number of documents)/(number of documents in which term appears)
IDF - measures how important a term is, this ensures that words that appear frequently in the document are weighed less. By using above Inverse document frequency formula frequently repeated words are weighed less.
I

After computing TF-IDF, we have to compute a matrix, which is array of vectors. In matrix each vector represents a book. Dimension of each vector will be the total number of unique words combined in all documents.
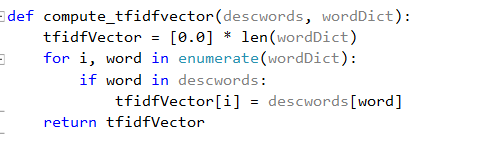
When the input is given for search, TF-IDF for each term in query are calculated
and this is converted to vector form.
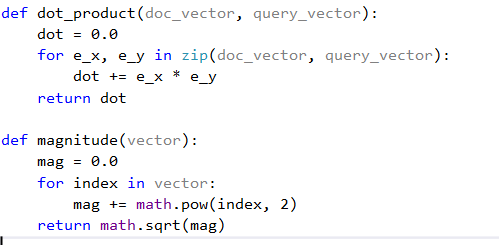
Using these two vectors we can calculate Cosine Similarity, which gives us how similar a search query is for every document.
Cosine(vector d, vector q) = dot product(vector d, vector q)/||vector d|| * ||vector q||

Using inverted index and lemmatization, I am narrowing down the search to documents in which the words are present. After finding matched documents, similarity score is calculated and documents with high similarity are displayed on top.
Phase Query Search
When searched with phrases, for examples if searched with two words, documents consisting of both the words are displayed. If one of the words is not in dataset then results for the other word are displayed.
Contributions
Implemented algorithm using optimal data structures.
Stored the tf-idf values and reused them throughout the application. I used JSON to store tf-idf values.
Using the tf-idfs in json file, document vectors, query vectors and their similarity score is computed in runtime for titles that match given query term which is reducing the search time.
Implemented phrase search. If exact phrase match is not found, will display results for words in phrase that match with dataset.
Challenges:
Data set is very huge finding optimized way to store data was challenging, using json files to store TF-IDF values and inverted index helped to improve text search speed.
Experiments
Execution time with and without inverted index

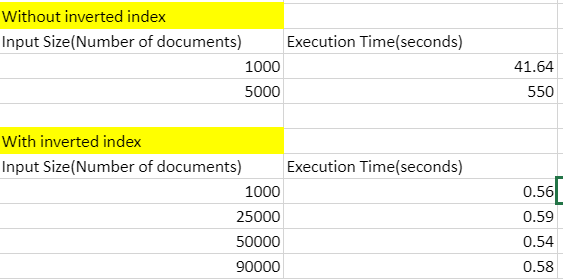
Observations from experiments:
Search after lemmatization:
Before lemmatization, search queries like "stronger", "happiest" returns documents only if words are an exact match.
After lemmatization: The same query will return documents that match with strong,happy etc.
Tokens after lemmatization:
Lemmatization normalizes words to dictionary form, but it needs additional information about part of speech of words. On using lemmatization I found following issue in my project.
Example:
"she leaves her friends and returns to the Institute, pretending to join Mr. Zetes. But when her reckless gamble goes wrong. light or darkness?"
dict_keys([ 'leaf', 'return', 'pretending', 'join', 'reckless', 'gamble', 'go', 'wrong', 'save', 'betray', 'final', 'battle', 'come', 'choose', 'light', 'darkness'])
Observed Issue:
Leaves is changed to leaf using lemmatization.
Porter Stemming:
Porter stemming is not stemming the word to original form
Observed Issue:
Query word- "Communication" (tokenized to ['commun'])
Search Results:
"The people of her community want justice...and Dani's learning that some thoughts are better left unsaid."
In above search results their is no word "Communication", but Porter Stemming returned results as communication is tokenized to "commun".
Above problems are solved using Snowball stemming:
Using Snowball stemming, above query word tokenized to ['communic']
No search results are returned as query word(communication) is not found in corpus.
Snowball Stemming:
Issue found in lemmatization is resolved using snowball stemming
"she leaves her friends and returns to the Institute, pretending to join Mr. Zetes. But when her reckless gamble goes wrong. light or darkness?"
tokens for above sentence
['leav', 'return', 'pretend', 'join', 'reckless', 'gambl', 'goe', 'wrong', 'save', 'betray', 'final', 'battl', 'come', 'choos', 'light']
As snowball stemming is handling issues found in Porter stemming and Lemmatization, it is better compared to lemmatization and Porter stemming. Hence we used snowball stemming in our project.
References
Project Site
Comments