Naive Bayes Classifier
- mbbhavana9
- Nov 12, 2019
- 2 min read
Updated: Dec 11, 2019
Classification is identifying to which class new data belongs to, given a number of classes.
In machine learning classifier utilizes training data to predict the class of data input given to it. In the Book data set, each book can have one or more classes, this is a multi label classification. I chose Naive Bayes classifier, as it is efficient in text classification.
Data Set
This book dataset consists of 100 classes. Hence I chose 6 most common classes. Also data set has records of books in more than 70 different languages. I chose records with language code "eng".

Pre-processing
Before applying the algorithm as a part of Data Preprocessing, data is tokenized, removed stop words and used snowball stemming.

Naive Bayes:
Probability of a new term belonging to a class is computed as:

For this, first we have to compute conditional probability of a term t in given genre (P{t/c}
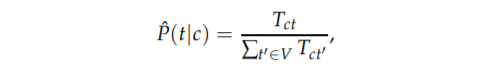
Computed conditional probabilities of word belonging to a class(P(t/c) and conditional probability of word not in class(P{t/c'))( i.e probability of word in all other classes).

Laplace Smoothing is done to avoid zero probability when the word doesn't appear in training data. For this smoothing value is added in numerator and denominator is adjusted by adding total number of words in data set.
Prior Probabilities: P{c} is number of terms in class c divided by total number of terms in all genres.

Now, conditional probabilities and prior probabilities can be used to calculated probability of genre given new query word.
Calculating genre probability for given query.
Given query statement is tokenized, stop words are removed and stemmed, then passed to below function to calculate probability of each class given term.

Evaluation:
For evaluation we split data set in 60:20:20 ratio for training, development and test respectively .
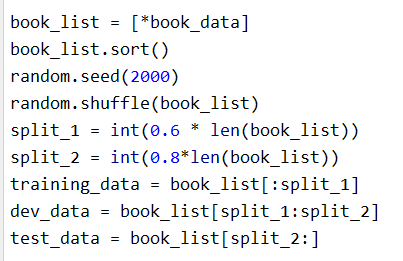
Using development data, hyper parameter smoothing value has been tuned to improve accuracy of training data.
Used below formulas for finding precision and recall
Yi -Ground truth labels assigned to document i
Zi - predicted labels for document i
n - total number of documents
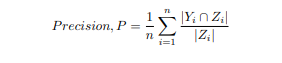




Observations:
Without Laplace smoothing recall value is higher than precision.
As precision is higher for smoothing value 0.01, we are choosing smoothing value as 0.01
Used test data to find accuracy and F1 value
Test data should be used only once as a final step to calculate accuracy and F1 value.
It should provide unbiased evaluation of training model.
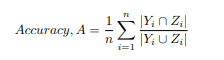
F1 = precision*recall/(precision+recall)
Accuracy is 40.13%
F1 value is 0.36
Contribution
Implemented Naive Bayes according to Dr.Park class lecture.
Performed hyper parameter tuning by changing smoothing value and evaluated the training model.
Challenges
Though Naive Bayes is simple. I faced difficulty in understanding Naive Bayes implementation for multi label dataset.
Also I had to do more research about Naive Bayes multilabel evaluation as it is different from other naive bayes models and I wanted to do it without using any frameworks.
Reference


Comments